I am captivated by anything related to computational social science, including machine learning, text mining, large language models, causal inference, networks, and spatial analysis. In most of my research, I either collect new data (e.g., through webscraping) or I employ innovative methods to gain new insights from existing data.
My main research topics are globalization, inequality, networks, and migration, but to paraphrase a famous statistician: The best thing about being a computational social scientist is that you get to play in everyone’s backyard. I have consulted on multiple projects in both academia and industry, related to text mining, predictive modelling, sampling, and much more. In my work, I mostly use Python, R, and SQL, but also Stata and SPSS.
Much of my work focuses on the impact of globalization on inequality. In my dissertation and in various related projects, I analyze how multinational corporations connect cities worldwide and to what extent these connections foster economic development. My dissertation was selected as runner-up for the 2024 Distinguished Ph.D. Dissertation Award at Indiana University. Another project in this line of work, won the World Society Foundation’s 2022 Paper Award.
As a Postdoctoral Fellow at Georgetown University, I work at the Massive Data Institute (MDI) and the Institute for the Study of International Migration (ISIM). In an interdisciplinary team of social scientists, computer scientists, and statisticians, I research how new data sources (e.g., digital trace data) can help predict and understand forced migration flows.
Globalization, Inequality, and City Development
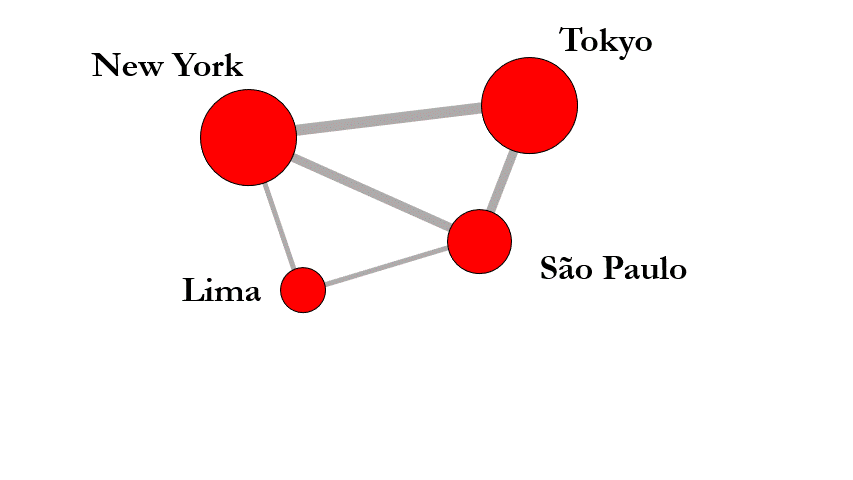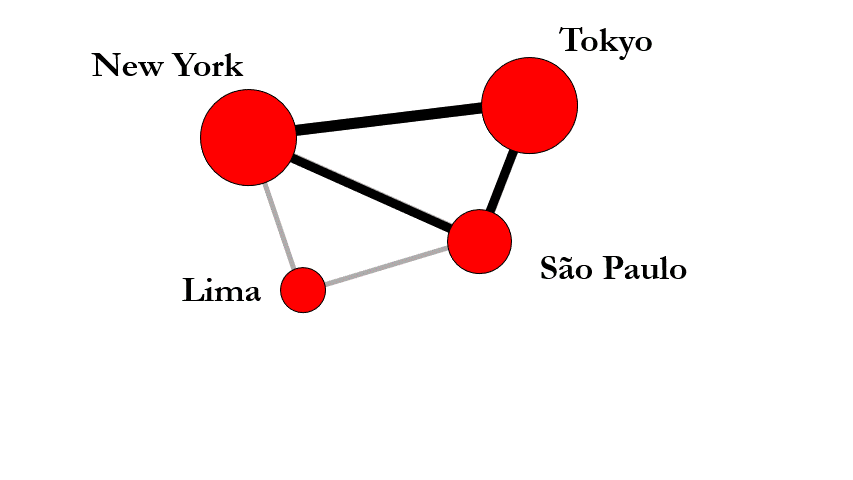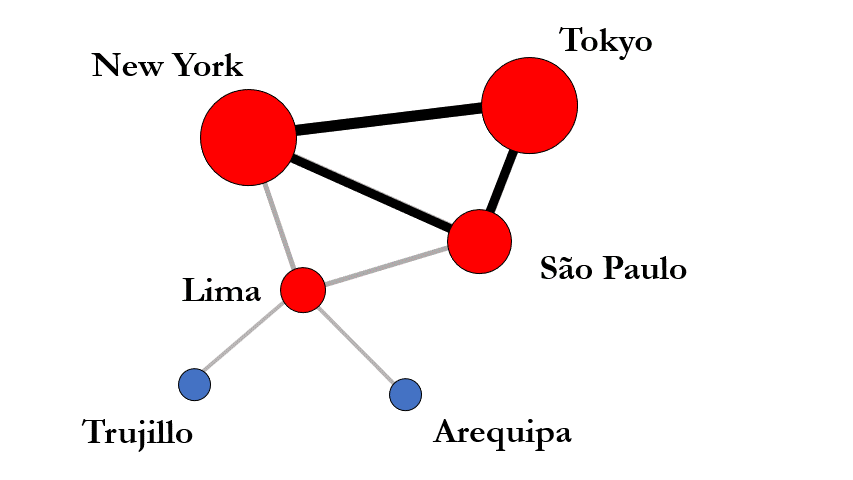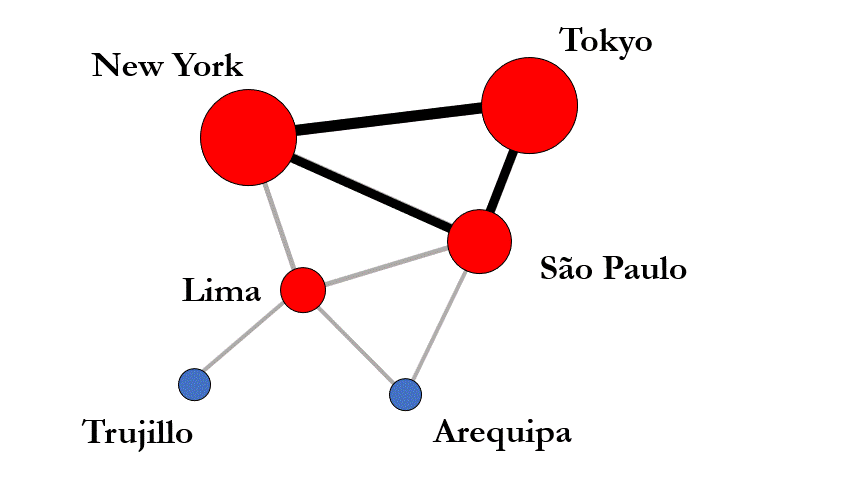
The impact of globalization on inequality seems self-contradictory: On the one hand, globalization opens new pathways of upward mobility and creates opportunities that would not exist without global supply chains, free flow of capital, and the activities of multinational corporations. On the other hand, globalization increases existing inequalities through “rich-get-richer”-effects. For example, companies might move to New York, or London, or Silicon Valley, simply because other companies are already located there. In this way, success breeds success, further increasing inequalities.
Between these tensions, I assess the impact of globalization on inequality employing techniques from machine learning, network science, and geography. Akin to individual level research on social mobility, my work illuminates how globalization changes the structure of opportunity and constraint that confronts cities by analyzing city mobility over time and between regions. Questions regarding globalization and inequality become ever more salient as we are entering a phase of slowed-down globalization or even deglobalization; one that will likely shape inequality over the next decades.
Forced Migration
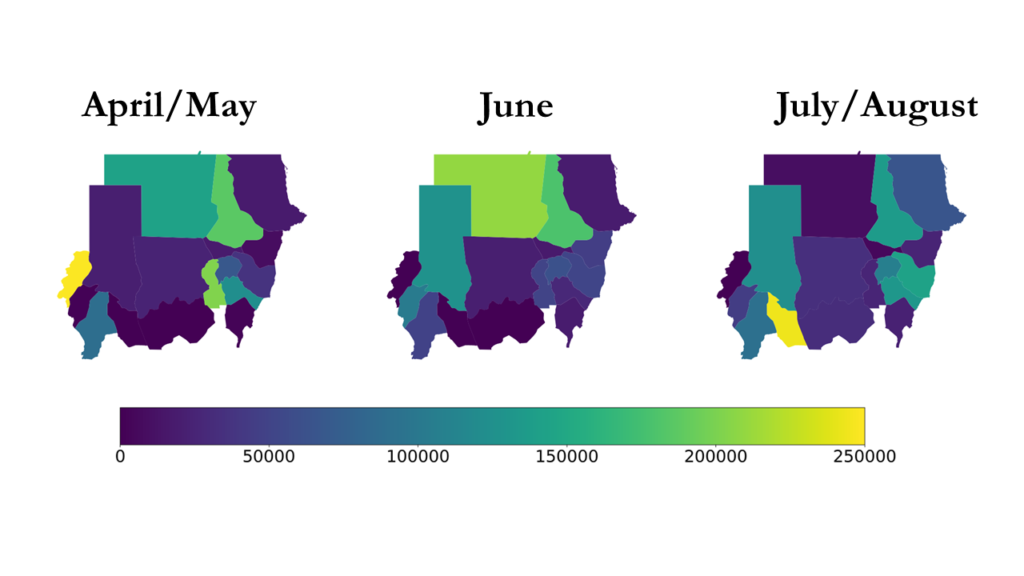
The number of people worldwide who are forced to flee has reached unprecedented heights and is projected to further increase as war, famine, and climate change worsen. While reliable movement data are essential to decision makers planning humanitarian response, data collection remains extremely challenging. As a Postdoctoral Fellow at Georgetown University, I work with a team of social scientists, computer scientists, and statisticians to explore new data sources (e.g., digital trace data) in the aim of developing faster and more effective responses to forced migration events. We have established a data-sharing partnership with the United Nations High Commissioner for Refugees (UNHCR) and the International Organization for Migration (IOM) and frequently collaborate with their analysts, updating them on our migration insights, which in turn shapes the humanitarian aid they dispense.
The figure above depicts the conflict in Sudan, which erupted in April 2023 and leaves 10M people internally displaced. Lighter colors indicate a higher number of people moving to a region. By modelling movement from one region to another, our goal is to better understand the causes and consequences of forced migration, and to predict movement in emerging crises.
Computational Social Science
I use new datasets (e.g. textual data from the Internet) and tools (e.g. machine learning methods) in my work. At Indiana University I taught a workshop series in Python that connected me with many other researchers who found that computational social science could contribute to their projects. The plot above comes from a project with a corpus of 80,000 local newspaper articles. I designed a sampling scheme and implemented a predictive model that flagged the 10,000 most relevant articles. Using the predictive model as opposed to a random sample significantly increased the percent of relevant articles in each year and newspaper.
Cosmopolitan Cultural Capital

Since the 1990s, sociologists have documented that elite tastes are distinguished by an increased volume and breadth. People with more money, education, and occupational status consume frequently and across traditional highbrow/lowbrow divides. More recent work also points to taste in foreign products as a main axis dividing taste by status. Here again, elites carry more ‘cosmopolitan cultural capital’, yet this could be just a by-product of more voluminous tastes in general. In this work, I examine this question using digital life data and taste in films.
The plot above shows a two-mode network of people and cultural products. Such networks are increasingly used to understand how fans and genres mutually define each other. I use them in combination with text mining methods to extract information on cultural tastes from unstructured textual data. For example, I trained a Named Entity Recognizer (NER) to flag favorite films and TV shows in online profiles.